Entrar

Es un software estadístico que provee todas las herramientas para la gestión, análisis y visualización de datos asociadas a una interfaz gráfica potente y a la vez fácil de usar. Stata cuenta con una gran diversidad de procedimientos estadísticos que pueden ser aplicados en diferentes áreas y sectores, por lo que es ampliamente utilizado en investigación académica así como en entidades gubernamentales, financieras, comerciales y de servicios.
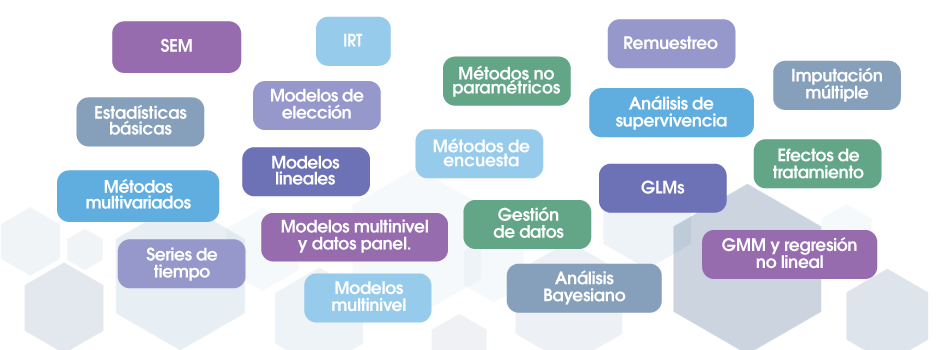
Cuando llega el momento de realizar sus análisis o comprender los métodos que está utilizando, Stata no lo deja solo, ni requiere gran cantidad de libros para aprender cada detalle.
Cada una de las funciones de administración de datos está completamente explicada y documentada, y se muestra en la práctica en ejemplos reales. Cada estimador está completamente documentado e incluye varios ejemplos de datos reales, con discusiones reales sobre cómo interpretar los resultados. Los ejemplos le brindan los datos para que pueda trabajar en Stata e incluso ampliar los análisis. Le brindamos un inicio rápido para cada función, que muestra algunos de los usos más comunes.
Stata es un paquete robusto con una gran cantidad de documentación: 36 manuales y más de 19000 páginas. Pero no se preocupe, con solo escribir help, Stata buscará sus palabras clave, índices e incluso paquetes aportados por la comunidad para brindarle todo lo que necesita saber sobre su tema. Todo esto está disponible dentro de Stata.
Por más de 40 años, Stata ha acompañado a cientos de de investigadores, académicos y analistas con lo necesario para la sus procesamientos estadísticos, contemplando desde gráficos y gestión de datos hasta procedimientos puntuales y avanzados. Algunas áreas con un uso muy importante de Stata son:
Ciencias del comportamiento
Bioestadística
Ciencia de datos
Ciencias económicas
Educación
Epidemiología
Finanzas, negocios y marketing
Investigación institucional
Medicina
Ciencias políticas
Salud pública
Políticas públicas
Sociología
STATA es un software estadístico y econométrico reconocido a nivel mundial, diseñado para análisis de datos, investigación académica y modelado avanzado. Permite trabajar con bases de datos grandes y aplicar técnicas de regresión, datos panel, modelos de series de tiempo y análisis multivariante.
A diferencia de otros paquetes, STATA combina potencia y flexibilidad con una interfaz intuitiva. Destaca por su rapidez al procesar grandes volúmenes de datos, la solidez de sus comandos, su amplia documentación y una comunidad académica activa que respalda su uso en universidades y centros de investigación.
STATA es ampliamente usado en academia, economía, salud pública, ciencias sociales, finanzas y políticas públicas. Su versatilidad la convierte en la herramienta ideal tanto para investigadores como para analistas de datos en instituciones privadas y gubernamentales.
No es necesario. STATA funciona mediante menús y comandos, lo que permite que usuarios principiantes trabajen con facilidad y que usuarios avanzados construyan scripts complejos para automatizar procesos y replicar estudios.
Puedes escribirnos a ventas@software-shop.com para recibir asesoría sobre las diferentes licencias disponibles (académicas, corporativas e individuales) y solicitar una demostración gratuita que te muestre cómo STATA puede adaptarse a tus proyectos de investigación o análisis de datos.
Stata cuenta con una agradable interfaz gráfica que se puede utilizar a través de ventanas o con una sintaxis de comandos intuitiva y potente que lo convierten en uno de los software estadísticos más completos y más fáciles de usar.
Todos los resultados que se obtienen pueden ser documentados para su publicación y revisión. El control de versiones asegura que las sintaxis de comandos sirvan en cualquiera de ellas, y los resultados que se obtengan sean los mismos, sin importar cuándo fueron escritos.
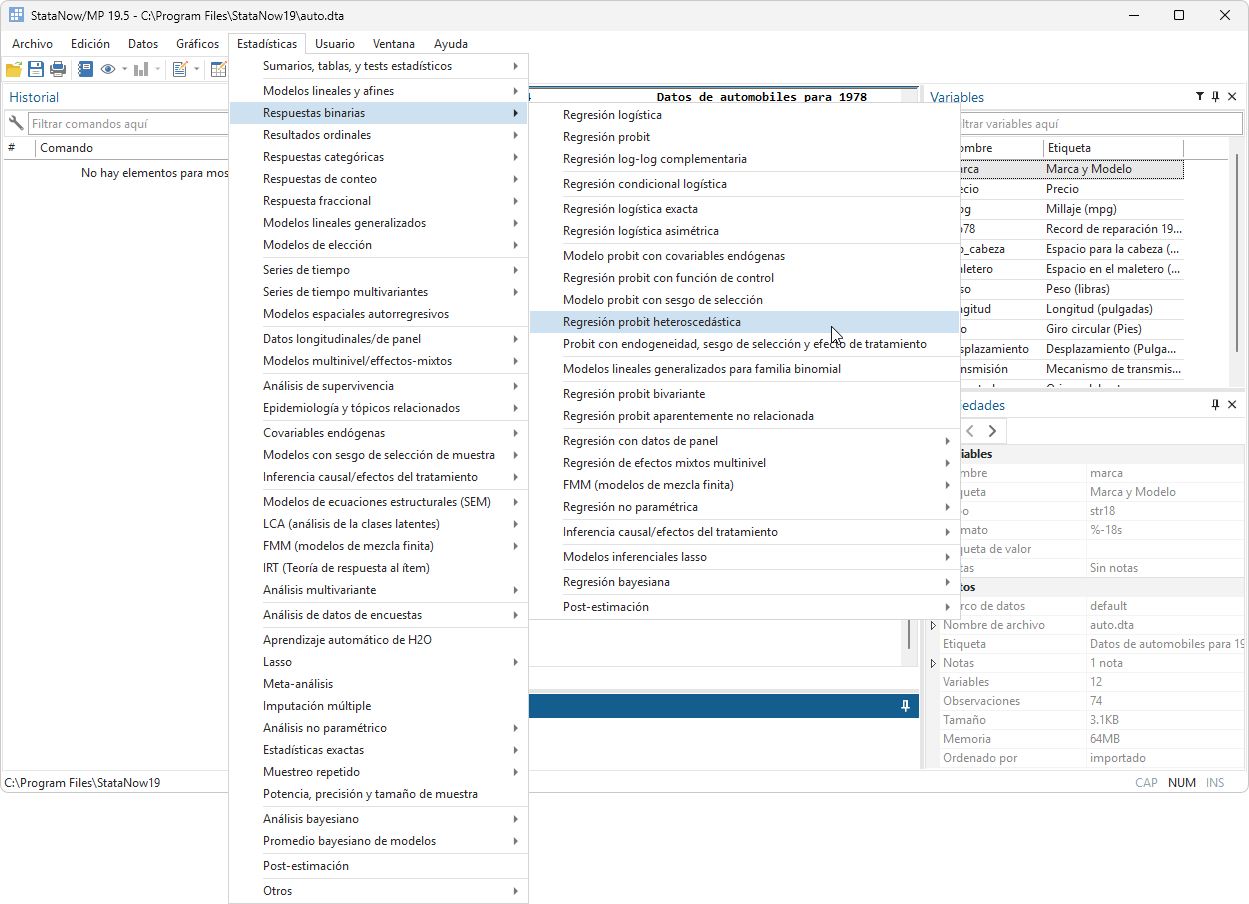
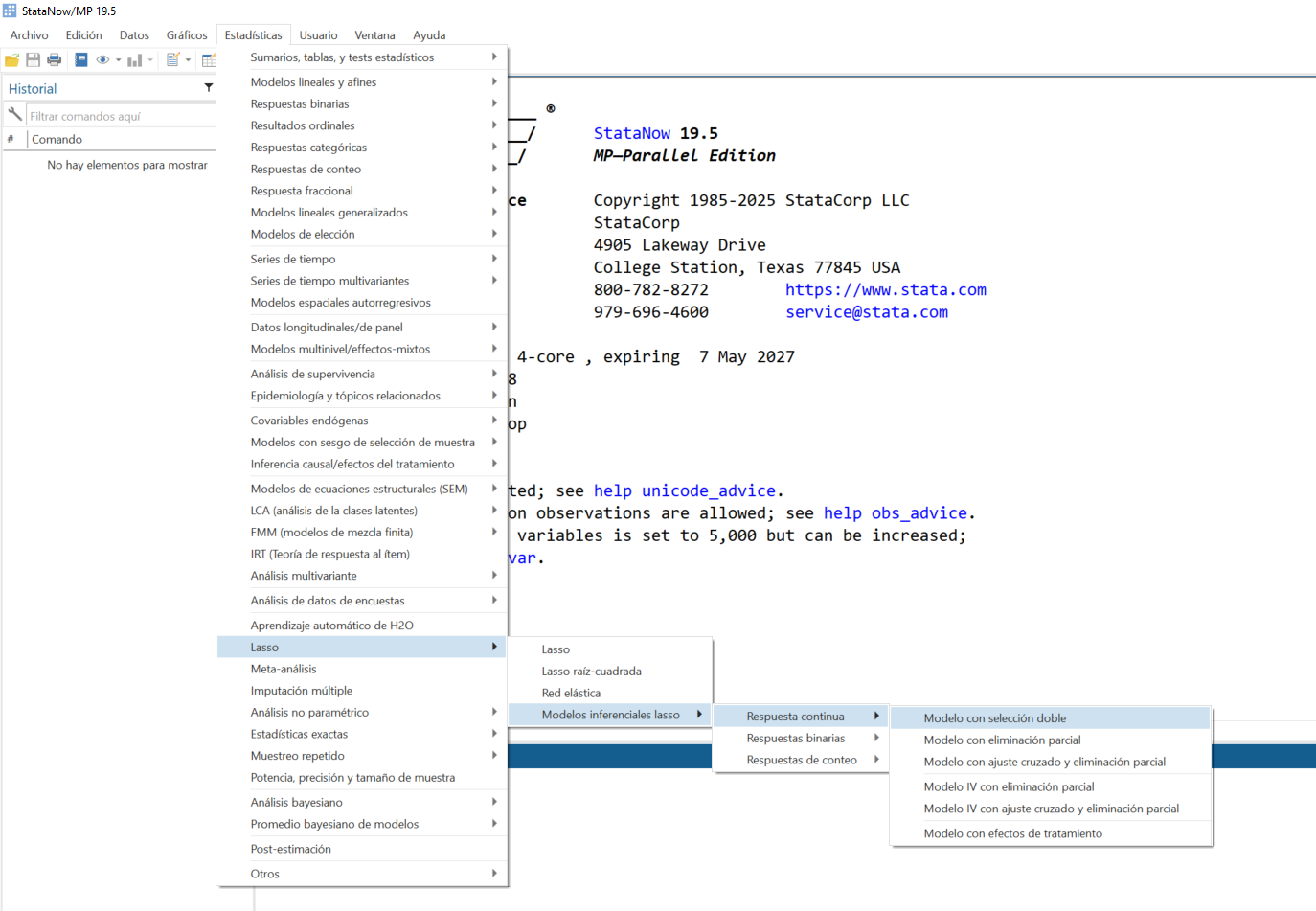
Dentro de su amplia gama de posibilidades, Stata permite una serie de funcionalidades para la gestión y manejo de grandes volúmenes de datos, facilita al usuario el trabajo y la importación de datos desde distintos formatos, entre ellos xls, csv, datos de texto con formato fijo, conexión a fuentes de datos ODBC e importación directa de archivos trabajados previamente en otros software.
Permite la combinación de conjuntos de datos (mediante las opciones merge y append), reportes de duplicados, creación y transformación de variables, agrupación o segmentación de datos mediante características previamente establecidas o bajo condiciones dadas, creación y visualización de filtros mediante expresiones múltiples.
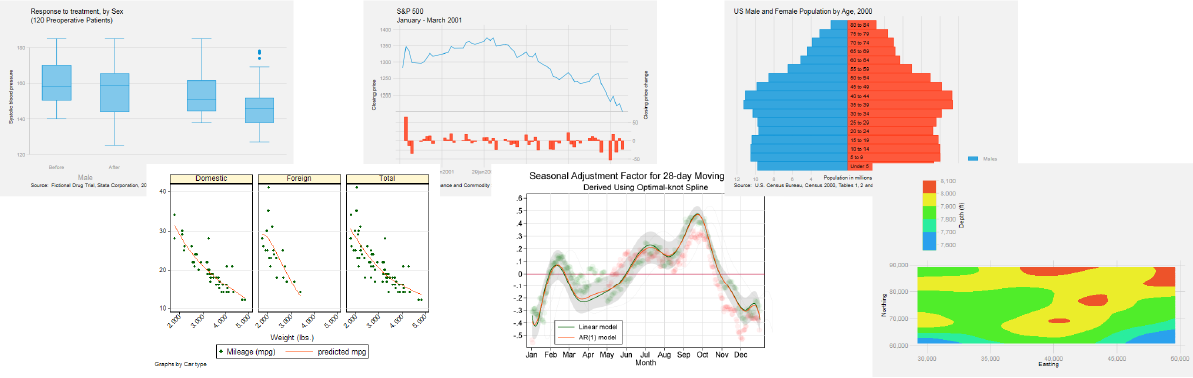
Usted puede señalar y hacer clic para crear un gráfico personalizado o, puede escribir secuencias de comandos para crear cientos de gráficos de forma reproducible. Puede exportar sus gráficos a EPS o a TIF para su publicación , a PNG o SVG para la web, o a PDF para su visualización. Con el editor de gráficos integrado puede cambiar cualquier aspecto del gráfico o agregar títulos , notas, líneas, flechas y texto.
Todas las herramientas que necesita para automatizar los informes de sus resultados.
Stata permite trabajar de forma interactiva el código Python dentro del ambiente de Stata, de igual forma, esta integración también permite llamar al código Stata desde entornos Python.
Utilice Stata dentro de Jupyter Notebook.
Transfiera datos y resultados sin problemas entre Stata y Python.
Utilice los análisis de Stata desde Python.
Use paquetes como:
Contar con la última versión de Stata ahora es más fácil que nunca. StataCorp desarrolla continuamente nuevas funciones para mejorar el software, estos cambios y actualizaciones van desde los últimos métodos estadísticos hasta lo mejor en informes, visualización de datos e interfaz de usuario. Con StataNow, se lanzan nuevas funciones a lo largo de la versión actual hasta la próxima versión..




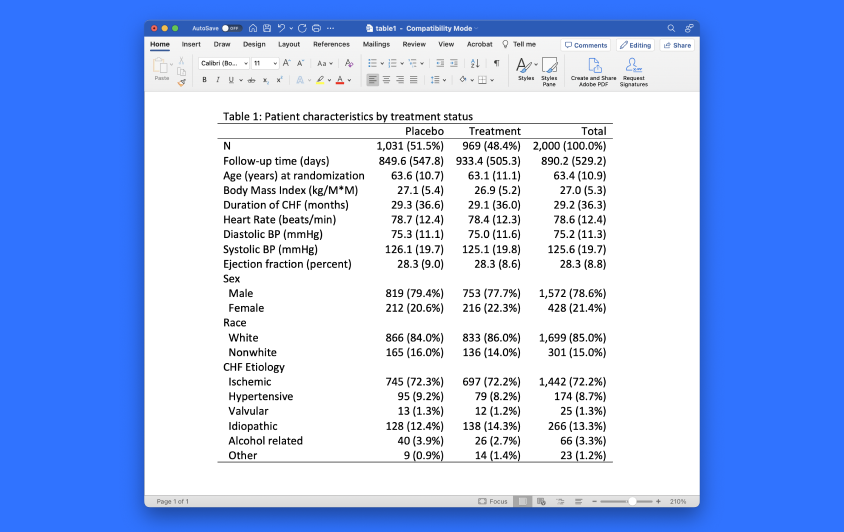



Cree fácilmente su Tabla con el nuevo comando dtable, resuma estadísticas descriptivas, compare información entre grupos y exporte facilmente a Word, Excel, PDF, HTML y más para incluir en informes.
Con dtable , crear una tabla de estadísticas descriptivas puede ser tan fácil como especificar las variables que desea en su tabla, está diseñado para que pueda crear y exportar una tabla a varios formatos en un solo paso. Por supuesto, puede personalizar la tabla incluyendo una variedad de estadísticas y datos relacionados.
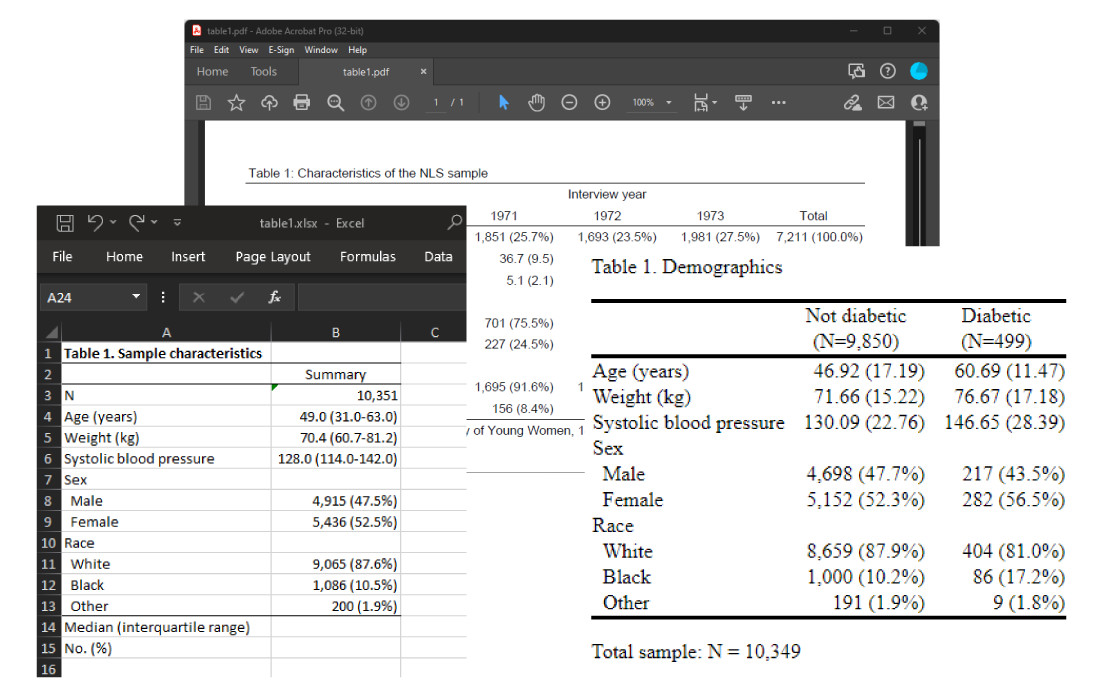
¿Por qué elegir un solo modelo cuando puede tomar información de varios? La nueva suite bma realiza un promedio del modelo bayesiano para tener en cuenta la incertidumbre del modelo en su análisis. ¿No está seguro de qué predictores incluir en su modelo de regresión lineal? con esta nueva opción puede usar bmaregress para averiguar qué predictores son importantes.
Con esta nueva suite realice la elección del modelo, la inferencia y la predicción. Utilice muchos comandos de posestimación para explorar modelos influyentes, complejidad de modelos, ajuste de modelos y rendimiento predictivo, análisis de sensibilidad a las suposiciones sobre la importancia de modelos y predictores, y más.
Stata se caracteriza por ofrecer a sus usuarios gráficos y reportes personalizados y de alta calidad para publicación, Stata 18, ofrece lo mejor de ambas opciones, en esta versión se han incluido los nuevos esquemas de gráficos stcolor , stcolor_alt , stgcolor y stgcolor_alt.
El nuevo comando mediate amplía la poderosa suite de inferencia causal de Stata para respaldar el análisis de mediación causal. El análisis causal identifica y cuantifica los efectos causales. El análisis de la mediación causal los desenreda. ¿Estos efectos están mediados por otra variable, un mediador?
Elija una de las 23 combinaciones de modelos de resultado y mediador, incluidos lineal, logit y Poisson, para estimar el efecto total y descomponerlo en efectos directos e indirectos (a través del mediador). Calcule los efectos directos controlados y mediados por proporciones. Reformule los efectos en proporciones de probabilidad, riesgo y tasa de incidencia, grafique los efectos estimados, obtenga predicciones y mucho más.

¿Diseñando un ensayo clínico? En Stata 18, puede usar los nuevos comandos gsbounds y gsdesign para calcular los límites de parada para ensayos secuenciales grupales.
gsdesign calcula límites de parada y tamaños de muestra para análisis intermedios con pruebas de medias, proporciones, funciones de supervivencia e incluso métodos definidos por el usuario, por su parte, gsbounds calcula los límites de eficacia y futilidad en función de la cantidad de análisis, también llamados miradas, el error de tipo I general deseado y la potencia deseada
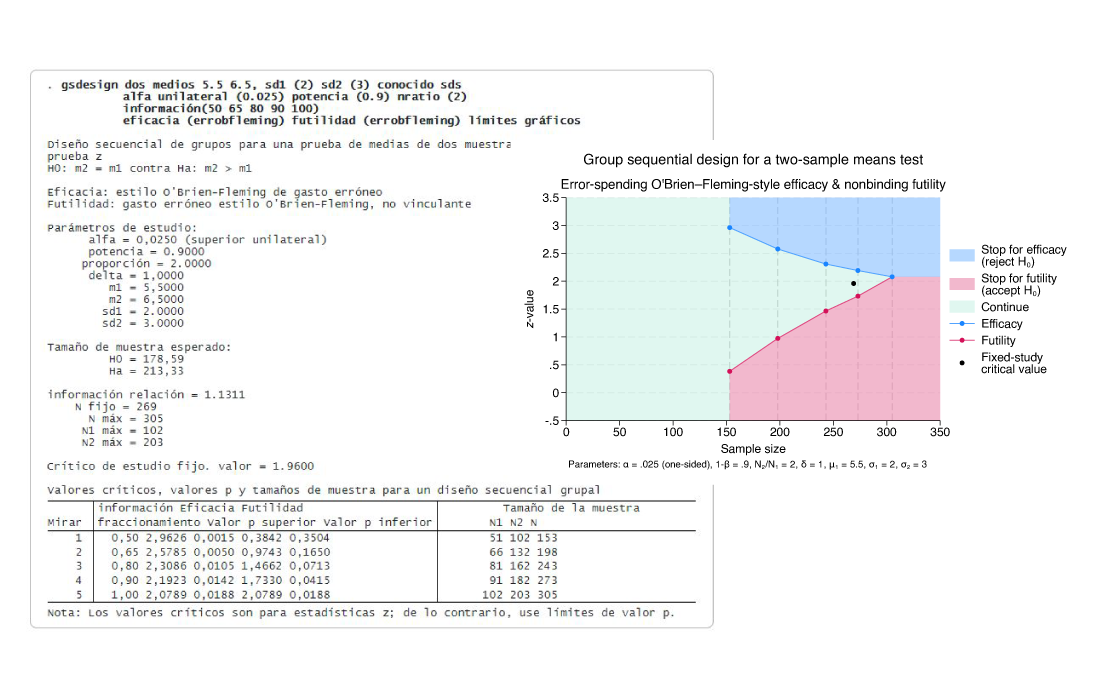
Stata 18 agrega dos nuevos comandos, meta meregress y meta multilevel. Incluya intersecciones aleatorias y coeficientes en diferentes niveles de jerarquía, y suponga diferentes estructuras de covarianza de efectos aleatorios, incluidas las intercambiables y las no estructuradas.
Realice un análisis de sensibilidad colocando varias restricciones en los componentes de varianza, evalúe la heterogeneidad, prediga efectos aleatorios y sus errores estándar comparativos y de diagnóstico.
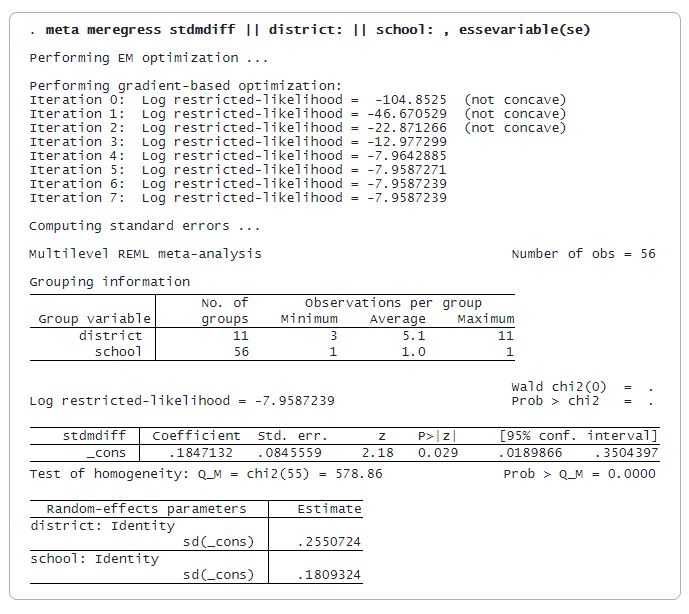
¿Cómo interactúan las exposiciones para aumentar el riesgo? ¿Sospecha que la interacción es aditiva? Use reri para averiguarlo. Se proporcionan tres medidas de interacciones bidireccionales: RERI, AP y SI. Se admiten muchos modelos que estiman el RR, incluidos el logístico, el lineal generalizado binomial y el de supervivencia.
El nuevo comando reri estima interacciones aditivas en modelos lineales generalizados binomiales; regresiones logísticas, de Poisson y binomial negativa; y Cox y otros modelos de supervivencia.
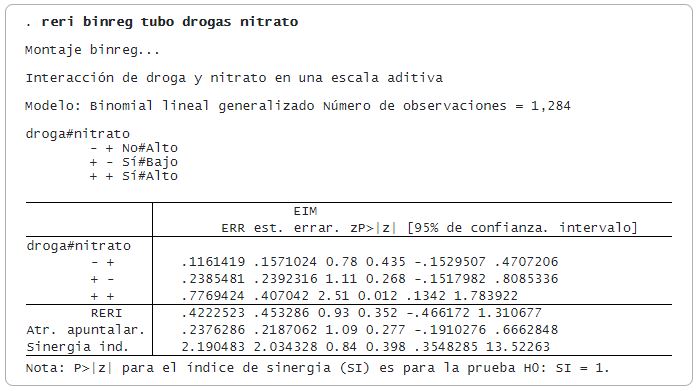
Cuando los efectos de tratamiento promedio varían con el tiempo y la cohorte, ahora puede usar los nuevos comandos hdidregress y xthdidregress para estimar los efectos de tratamiento promedio heterogéneos en los tratados (ATET). Utilice hdidregress con datos transversales repetidos y xthdidregress con datos de panel.
Elija uno de los cuatro estimadores, incluido el ajuste de regresión y la ponderación de probabilidad inversa, trace perfiles de tiempo de ATETs para cada cohorte con estat atetplot. Agregue los ATETs dentro de la cohorte, el tiempo y la exposición al tratamiento con estat aggregation, además explore más funciones de postestimación.
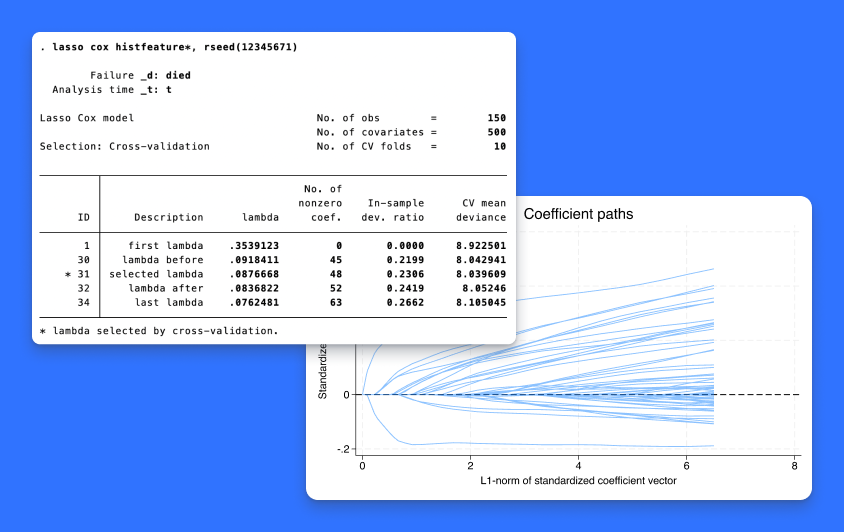
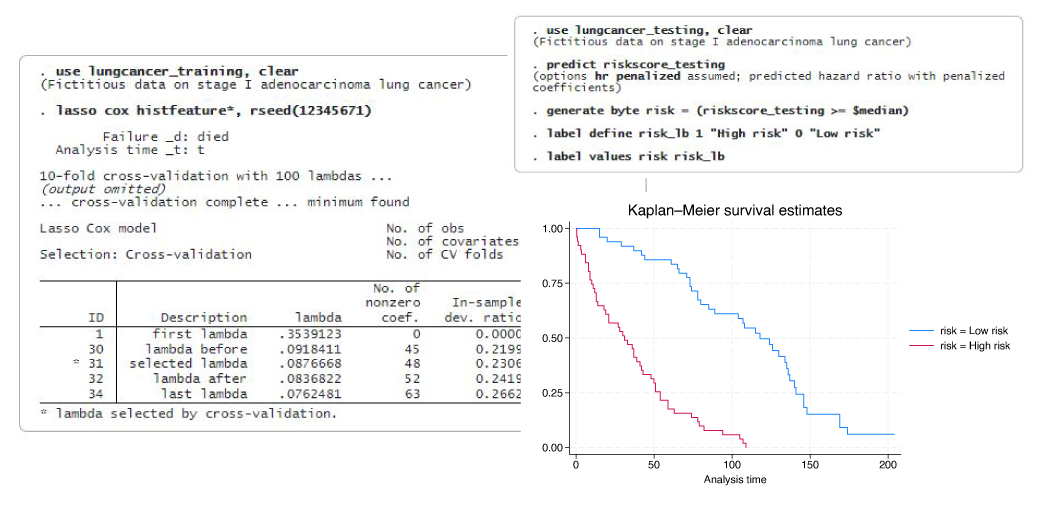
Si tiene datos de tiempo de supervivencia o tiempo de falla, y muchos predictores, consulte los comandos lasso cox y elasticnet cox que amplían la suite lasso existente para predicción y selección de modelos para incluir un modelo semiparamétrico de riesgos proporcionales de Cox de alta dimensión.
Después de lasso cox y elasticnet cox, puede usar stcurve para trazar la función de supervivencia, falla, riesgo o riesgo acumulativo o usar cualquiera de las otras herramientas de postestimación disponibles después de lasso y elasticnet.
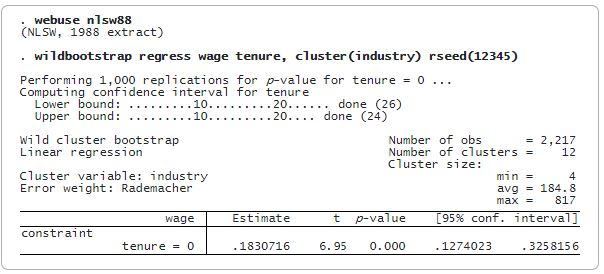
¿Sus datos tienen un pequeño número de conglomerados o un número impar de observaciones por conglomerado? ¿Quiere hacer inferencias sobre parámetros en un modelo lineal? Con el nuevo comando wildbootstrap, puede usar wild cluster bootstrap (WCB) para resolver estas situaciones
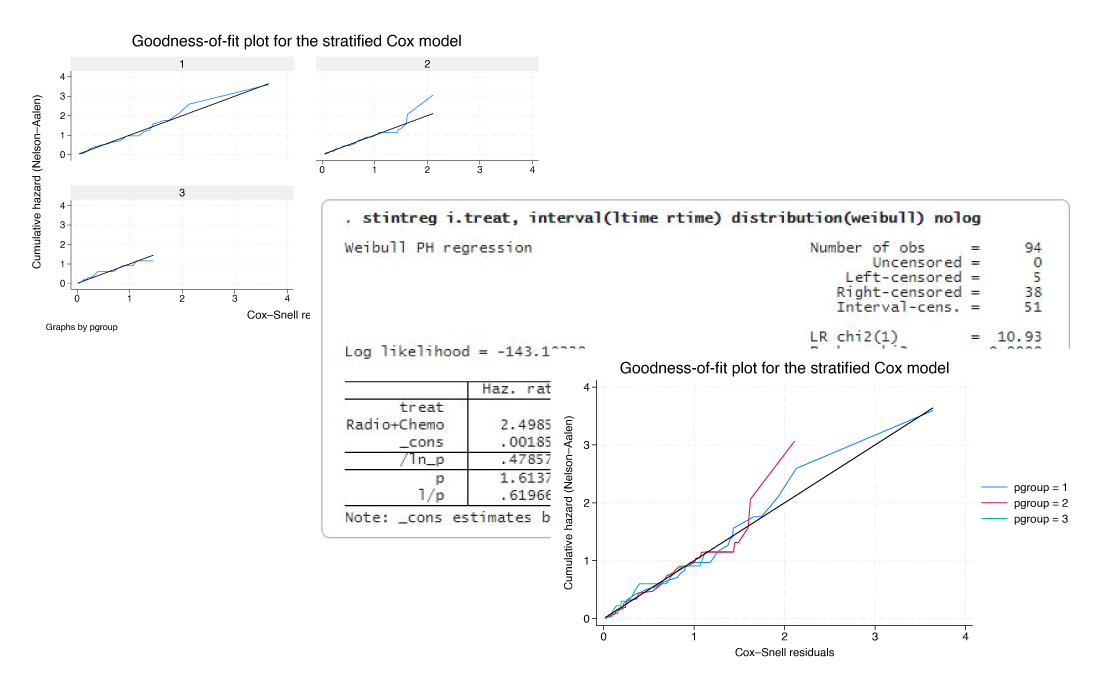
Stata 18 proporciona el nuevo comando estat gofplot para producir diagramas de bondad de ajuste (GOF) para modelos de supervivencia.
Puede usarlo después de cuatro modelos de supervivencia: Cox censurado por la derecha (stcox), Cox censurado por intervalos (stintcox), paramétrico censurado por la derecha (streg) y paramétrico censurado por intervalos (stintreg). Verifique el ajuste del modelo después de los modelos estratificados o por separado para cada grupo. Los diagramas GOF proporcionan comprobaciones visuales de qué tan bien se ajusta el modelo a los datos.
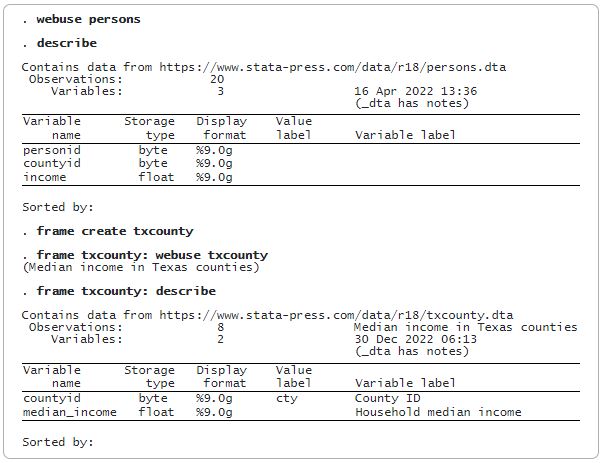
Stata admite múltiples conjuntos de datos en la memoria, cada conjunto de datos reside en un marco o frame. En Stata 18, ahora puede trabajar con variables de diferentes marcos como si existieran en uno.
Las variables de alias, creadas por el nuevo comando fralias add, definen referencias a variables en marcos vinculados. Estas variables ocupan muy poca memoria porque las observaciones en realidad se almacenan en otro marco. Stata trata las variables de alias como cualquier otra variable en su conjunto de datos, con la excepción de que no puede cambiar sus valores.
Cuando queremos estudiar los efectos de las covariables en diferentes cuantiles del resultado, usamos la regresión por cuantiles. Pero ¿y si sospechamos que una covariable es endógena? El nuevo comando ivqregress permite modelar los cuantiles del resultado y, al mismo tiempo, controla los problemas que surgen de la endogeneidad.
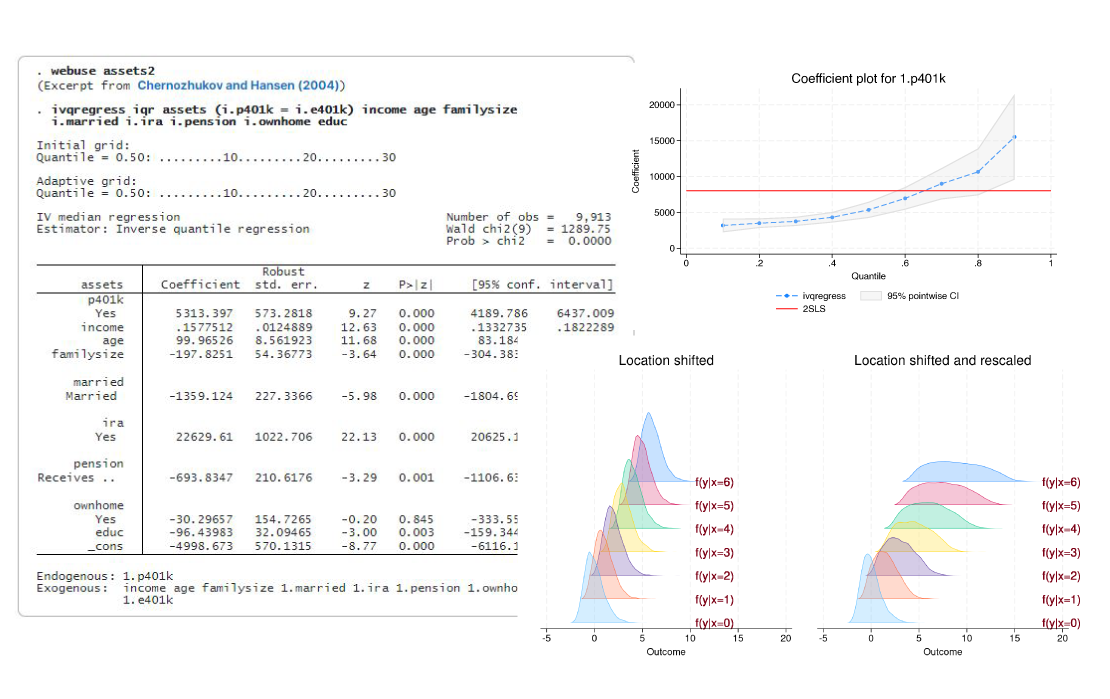
¿Quiere encontrar el mejor modelo ARIMA o ARFIMA para sus datos? Compare modelos potenciales utilizando AIC, BIC y HQIC. Utilice los nuevos comandos arimasoc y arfimasoc para seleccionar la mejor cantidad de términos autorregresivos y de promedio móvil.
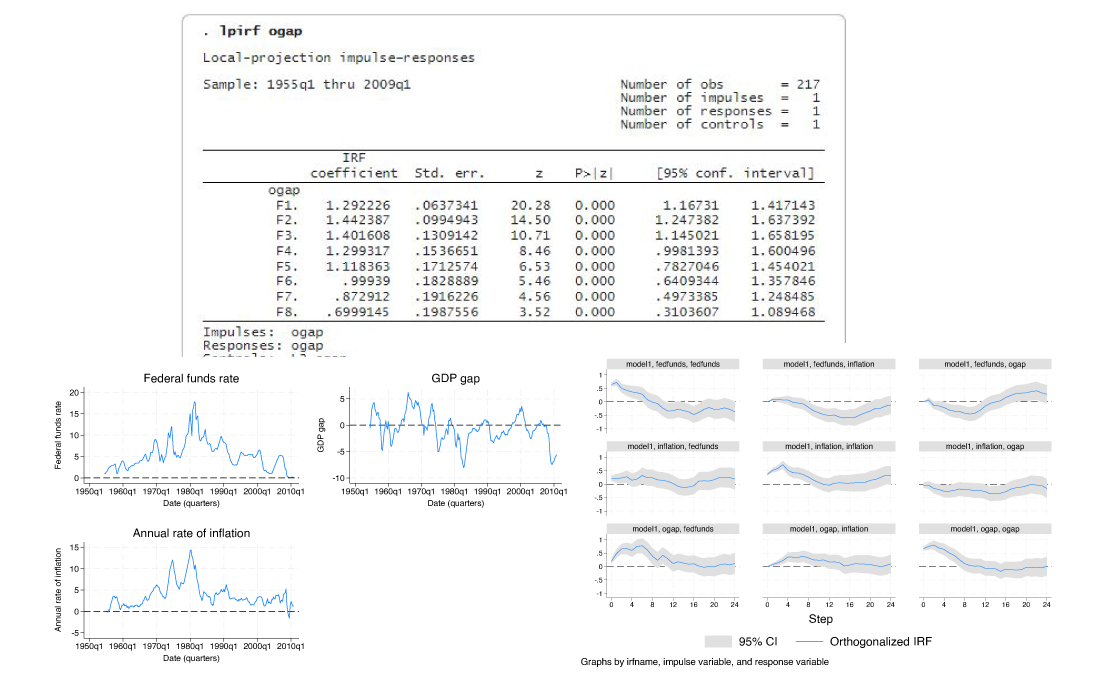
Con las funciones de impulso-respuesta, puede averiguar cómo una perturbación en una variable afecta a otras variables a lo largo del tiempo. Con las proyecciones locales, puede estimar funciones de impulso-respuesta directamente mediante regresiones de varios pasos. Utilice el nuevo comando lpirf para estimar las proyecciones locales y graficarlas o tabularlas con la suite irf.
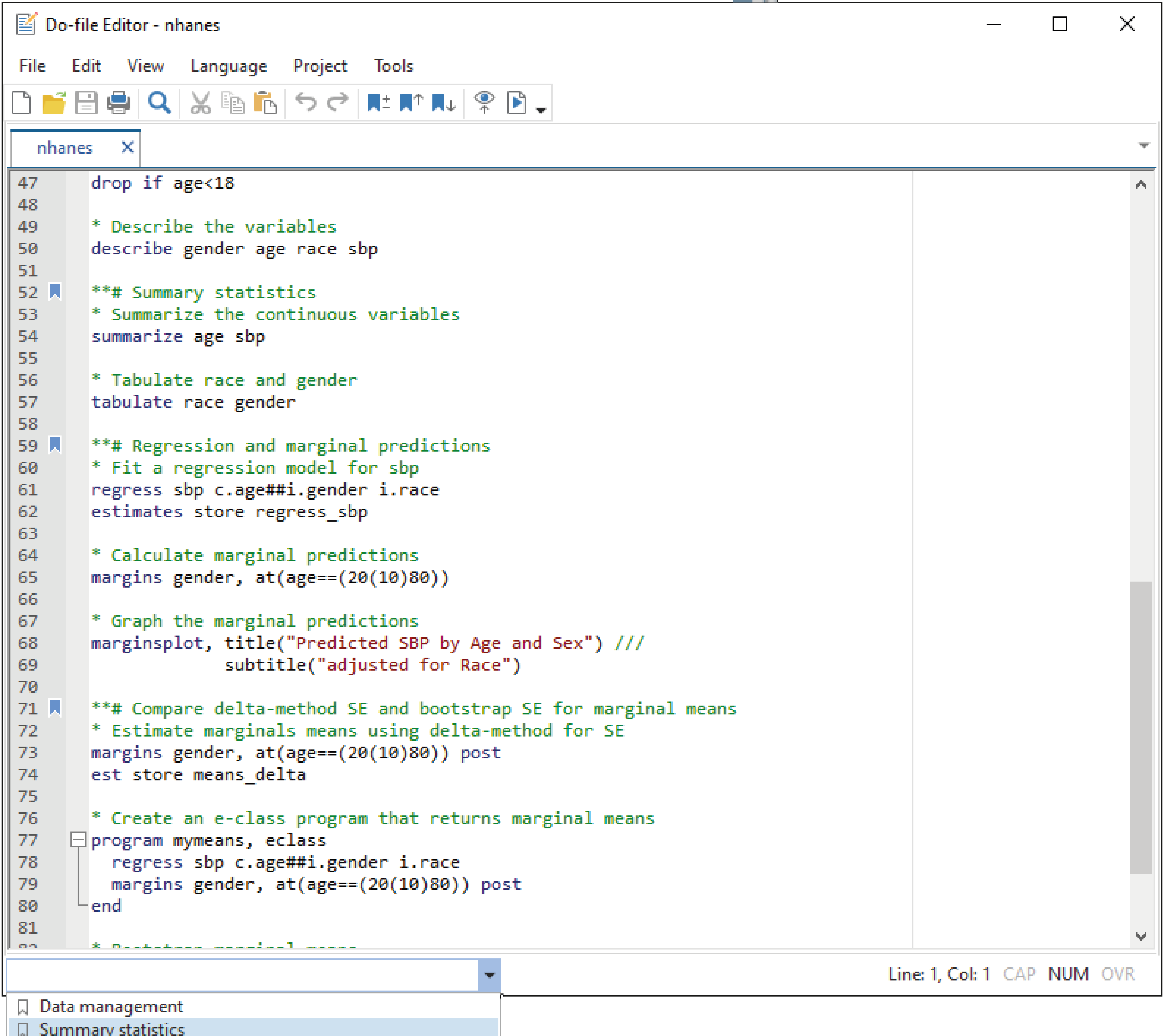
El editor de archivos Do en Stata 17 incluye las siguientes mejoras:
Marcadores: Los marcadores se utilizan para marcar líneas de interés y volver a ellas más tarde con mayor facilidad, son particularmente útiles para navegar por archivos Do extensos.
Control de navegación: Stata 17 facilita la navegación en los archivos Do con el nuevo Control de Navegación, que muestra una lista de marcadores y sus etiquetas.
Stata en su versión 17 ha agregado nuevas funciones para el manejo de fechas y horas tanto en Stata como en Mata.
Las nuevas funciones tienen en cuenta los años y meses bisiestos, según corresponda. Estas se pueden agrupar en tres categorías:

Conectar Stata con bases de datos se ha vuelto aún más fácil puesto que Stata 17 agrega soporte para JDBC (Conectividad a bases de datos de Java). JDBC es un estándar multiplataforma para intercambiar datos entre programas y bases de datos.
Puede importar datos desde algunos de los proveedores de bases de datos más populares, como Oracle, MySQL, Amazon Redshift, Snowflake, Microsoft SQL Server y muchos más, esta opción corresponde a una solución multiplataforma, por lo que, funciona de la misma manera para los sistemas Windows, Mac y Unix.
Ahora puede insertar y ejecutar código Java directamente en Stata. En versiones anteriores era posible usar complementos de Java, sin embargo, eso requería compilar y empaquetar en un archivo Jar.
La ejecución de Java en un archivo Do le da la libertad de ejecutar código Java vinculado directamente a su código de Stata.
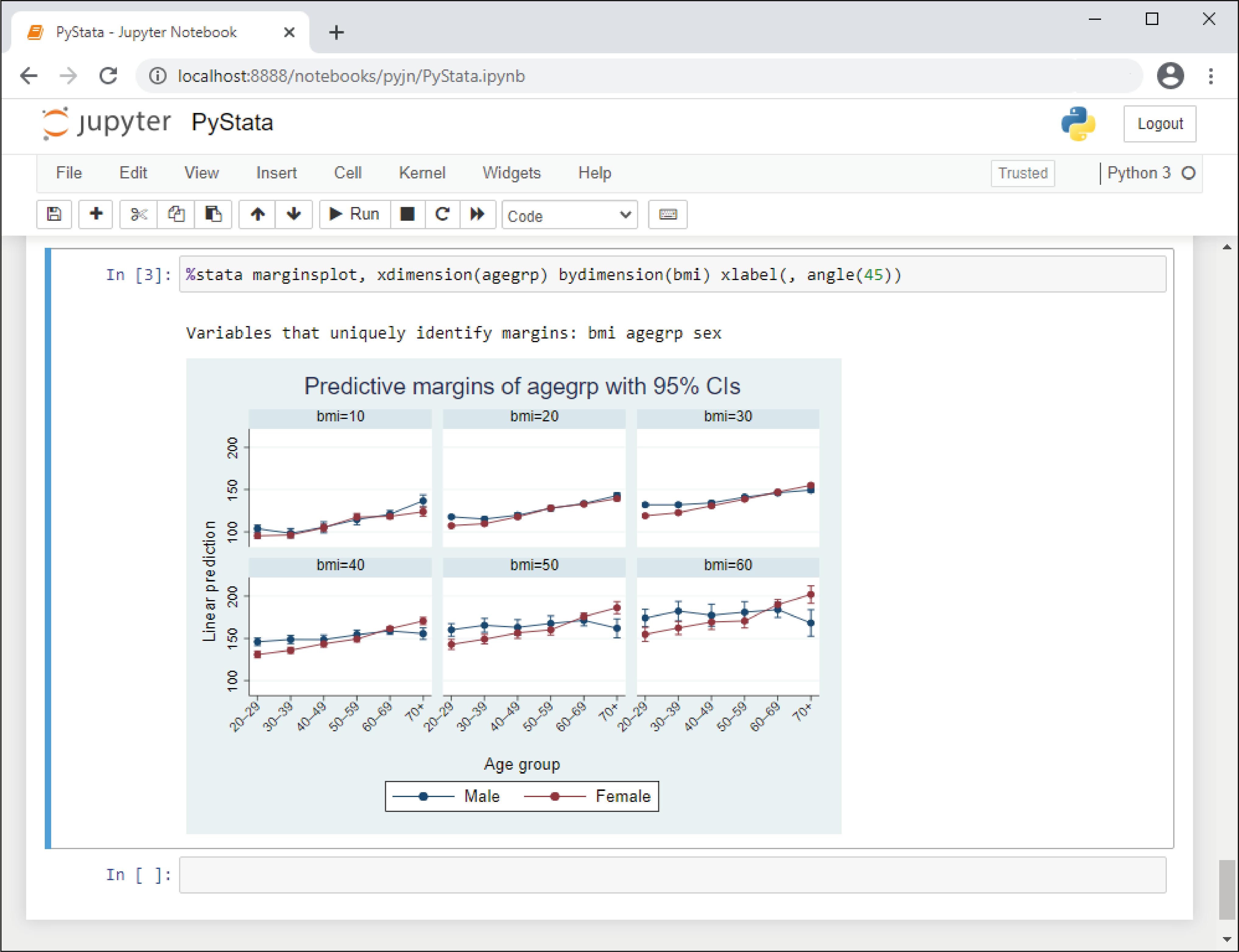
pystata es un término que abarca todas las formas en que Stata y Python puede interactuar, este término es introducido en Stata 17. El paquete pystata Python permite llamar a Stata desde su entorno Python independiente. Además, acceda a Stata y Mata cómodamente en un entorno basado en kernel de Python.
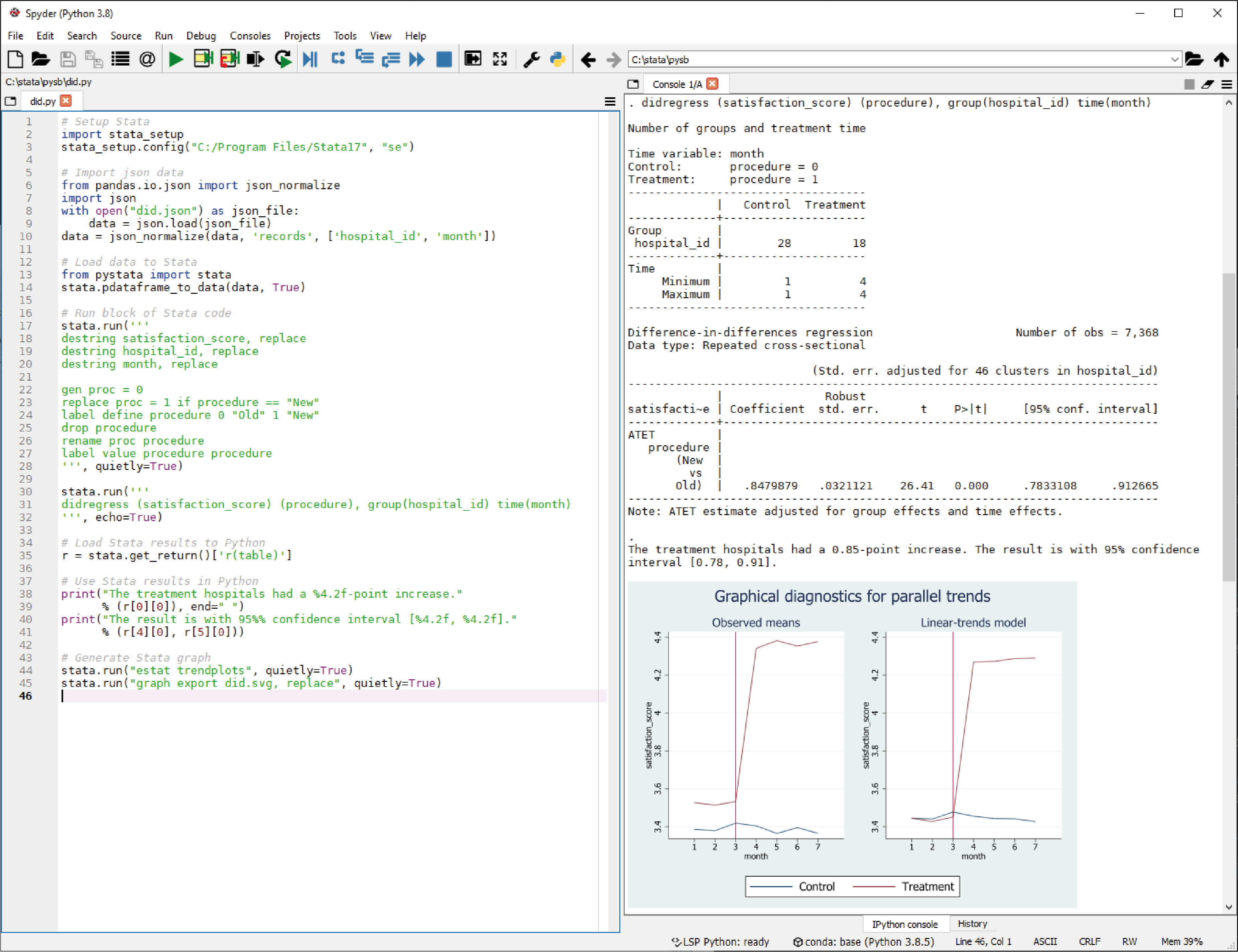
Jupyter Notebook es una aplicación web potente y fácil de usar que le permite combinar código ejecutable, visualizaciones, ecuaciones y fórmulas matemáticas, texto narrativo, entre otros, en un documento único o cuaderno para el desarrollo.
Esta opción es ampliamente utilizada por investigadores y científicos, para compartir sus ideas y resultados. También, Python permite llamar a Stata y Mata desde Jupyter Notebook.
Stata/MP*La edición más rápida de Stata para base de datos grandes |
Stata/SEEdición estándar para conjuntos de datos más grandess |
Stata/BEEdición básica para conjuntos de datos medianos |
|
| # observaciones | 20 Billones | 2,14 Billones | 2,14 Billones |
|---|---|---|---|
| # de variables | 120,000 | 32,767 | 2,048 |
| Máximo # de variables independientes | 65,532 | 10,998 | 798 |
| # de caracteres en un comando | 15,480,216 | 4,227,159 | 264,408 |
* Disponible para procesadores de 2, 4, 6, 8, 10, 12, 16, 24, 32, 64 núcleos.
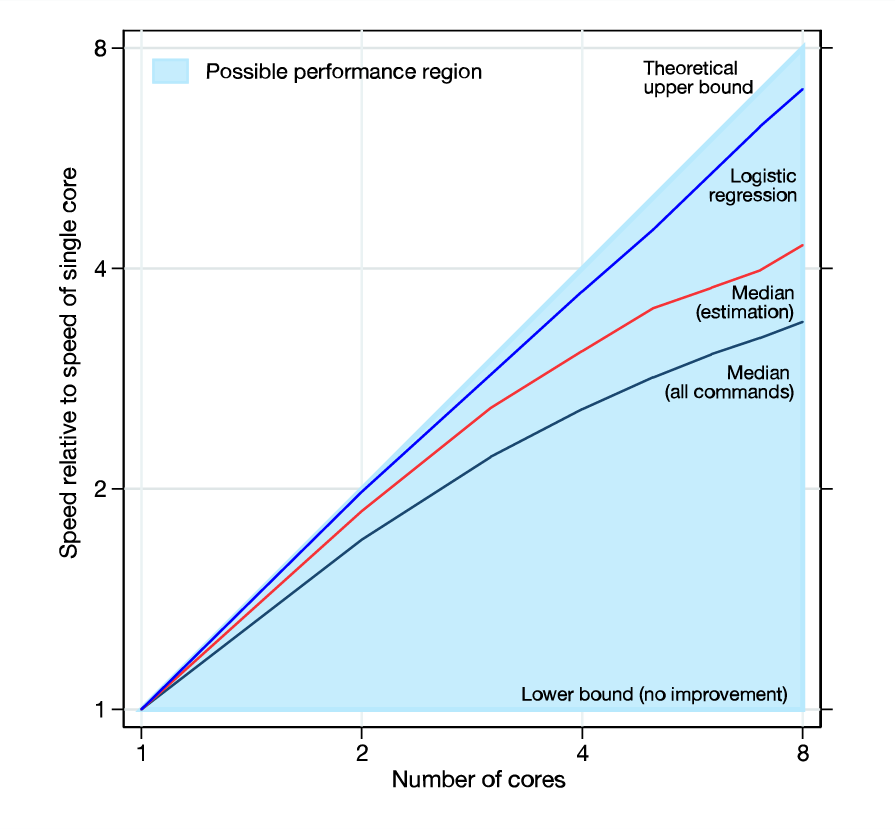
Stata/MP cuenta con ediciones adecuadas a las características y capacidad de cada máquina, permitiendo optimizar la velocidad de procesamiento de datos, ya sea en una computadora personal o en un servidor. En la gráfica adjunta se muestra la relación de la velocidad para la ejecución de una regresión lineal dependiendo de los núcleos del procesador, (comando regress).
La velocidad es a menudo más crucial cuando se realizan procedimientos de estimación computacionalmente intensos. Algunos de los procedimientos de estimación de Stata, incluida la regresión lineal, están casi perfectamente paralelizados, lo que significa que se ejecutan dos veces más rápido en dos núcleos, cuatro veces más rápido en cuatro núcleos, ocho veces más rápido que rápido en ocho núcleos, y así sucesivamente. Algunos comandos de estimación se pueden paralelizar más que otros. Tomados en la mediana, los comandos de estimación se ejecutan 1.7 veces más rápido en 2 núcleos, 2.6 veces más rápido en 4 núcleos y 3.4 veces más rápido en 8 núcleos.
La velocidad también puede ser importante cuando se administran grandes conjuntos de datos. La adición de nuevas variables se paraleliza casi en un 100 por ciento y la clasificación se paraleliza en un 61 por ciento.
Información detallada sobre el rendimiento de cada una de las ediciones puede encontrarse aquí. Sin embargo, en resumen, puede mencionarse que:
*64-bit para procesadores x86-64 hechos por Intel® y AMD
| Edición | Memoria | Espacio del disco |
|---|---|---|
| Stata/MP | 4 GB | 4 GB |
| Stata/SE | 2 GB | 4 GB |
| Stata/BE | 1 GB | 4 GB |
*Stata para Lunix requiere de una tarjeta de video que pueda visualizar miles de colores o más (16-bit o 24-bit color)
Para licenciamiento corporativo, de gobierno o licenciamiento múltiple para instituciones educativas puede solicitar una cotización o escribirnos a ventas@software-shop.com para preguntas inmediatas puede acceder al chat virtual.

Stata es un software completo e integrado que provee todo lo que necesitas para la gestión, análisis y visualización de datos con una interfaz amigable y fácil de usar. Cuenta con una amplia gama de funciones estadísticas que incluyen procedimientos especializados para epidemiología, ciencias sociales, economía, psicología y muchas disciplinas más. Para estudiantes, Stata tiene una edición que se ajusta a tus necesidades.
Con cualquiera de estas ediciones accedes a todas las funciones estadísticas de Stata, incluyendo compatibilidad con Python, reportes reproducibles, trabajo simultáneo con diferentes conjuntos de datos y más.

Edición básica: para conjuntos de datos de tamaño medio.
$46 USD
(6 meses)

$92 USD
(Anual)
En caso de devolución de pago, por causas atribuibles al comprador, se hará un cargo de USD$10 por Gastos Administrativos.

Edición estándar: para conjuntos de datos más grandes.
$95 USD
(6 meses)
$177 USD
(Anual)
En caso de devolución de pago, por causas atribuibles al comprador, se hará un cargo de USD$10 por Gastos Administrativos.
Somos el distribuidor autorizado de Stata para el territorio Latinoamericano, representando a la marca desde hace más de 17 años. Como parte de esta asociación, desarrolla material en español, facilita compras locales del producto y realiza apoyo a los clientes en su idioma y horarios.
Con Software Shop puede adquirir licencias empresariales, académicas o sin fines de lucro en México, Guatemala, Belice, El Salvador, Honduras, Nicaragua, Costa Rica, Panamá, Cuba, República Dominicana, Colombia, Venezuela, Ecuador, Perú, Bolivia, Chile, Argentina, Uruguay, Paraguay.
Adicionalmente, Software Shop cuenta con exclusividad en Colombia, Chile, Perú y Ecuador
Consulte el distribuidor autorizado para su territorio en:
https://www.stata.com/worldwide/?country=ColombiaPara adquirir Stata o solicitar una demostración gratuita, solo debe contactar a nuestro equipo de ventas en ventas@software-shop.co. Le proporcionaremos detalles sobre licencias académicas, corporativas y personales.
Instalar Stata en su computadora es un proceso sencillo y rápido. El software es multiplataforma, por lo que puede instalarlo tanto en Windows como en Mac o Linux sin inconvenientes. Solo debe descargar el instalador, además, recibirá una guía de instalación que le acompañará paso a paso.
Aprender a usar Stata es sencillo, incluso para quienes no tienen experiencia previa en análisis de datos. Stata cuenta con una interfaz intuitiva que permite a los usuarios que inician trabajar rápidamente mediante menús, pero también ofrece potentes herramientas de comando para usuarios más avanzados. Además, Stata tiene una amplia documentación en línea, tutoriales y una comunidad activa que facilita el aprendizaje. Ya sea que esté comenzando en análisis estadístico o buscando automatizar procesos, Stata tiene recursos para todos los niveles.
Es el tipo de licenciamiento en Stata que recibe actualizaciones continuas. Con StataNow, el software se mantiene siempre actualizado y adaptado a las últimas tendencias y avances en análisis estadístico, ofreciéndo una experiencia óptima y a la vanguardia.
Hemos encontrado 2
registros.
Página 1 de 1
Abr
10
2026
May
29
2026
Hemos encontrado 15
registros.
Página 1 de 1
Descrubre las novedades Stata 19. En su más reciente versión, Sta...
La visualización de información geoespacial mediante mapas es una he...
...
Stata es una de las herramientas más completas para el análisis de d...
En proyectos de análisis de datos cada vez más complejos, surge la n...
Es un software estadístico que provee todas las herramientas para la ...
El uso de herramientas especializadas para la enseñanza de la estadí...
En esta presentación se realizará una introducción al manejo de dat...
Explorar, resumir y comparar son tareas fundamentales para el análisi...
En Ciencias de la Salud, tanto el ahorro de tiempo como la precisión ...
En la actualidad, el análisis de grandes volúmenes de información y...
Stata es una de las herramientas más completas para el análisis esta...
En nuestro portafolio cuantitativo encontrarás <b>herramientas y meto...
Stata es uno de los software más completos para el análisis de datos...
En labores de investigación, es fundamental conocer los conceptos bá...



















Edición básica: para conjuntos de datos de tamaño medio.

Stata/MP es la edición más rápida y con mayor capacidad de análisis de datos de Stata. Puede trabajar con procesadores de hasta 64 núcleos. Stata/MP puede analizar de 10 a 20 billones observaciones en diferentes computadores.

La edición de Stata para bases de datos a gran escala. Stata/SE permite analizar hasta 32767 variables y cerca de 2000 millones de observaciones.

Suscripción a Stata Journal
Mantenimiento
Prof+ Plan








































Abr
09
2026
Abr
09
2026
Abr
10
2026

Abr
15
2026
Abr
16
2026

Abr
17
2026
Abr
21
2026
 LATAM
LATAM

Abr
24
2026
May
29
2026





